1. Memcached 分布式原理
添加新的键值对数据

从图中可以看出,Memcached 虽然称为“分布式”缓存服务器,但服务器端并没有“分布式”功能,而是完全由客户端程序库实现的。服务端之间没有任何联系,数据存取都是通过客户端的算法实现的。当客户端要存取数据时,首先会通过算法查找自己维护的服务器哈希列表,找到对应的服务器后,再将数据存往指定服务器。例如:上图中应用程序要新增一个
<'tokyo',data>的键值对,它通过 set 操作提交给 Memcached 客户端,客户端通过一定的哈希算法(比如:一般的求余函数或者强大的一致性 Hash 算法)从服务器列表中计算出一个要存储的服务器地址,最后将该键值对存储到计算出来的服务器里边。获取已存在的键值对数据

上图中应用程序想要获取 Key 为 tokyo 的 Value,于是它向 Memcached 客户端提交了一个 Get 请求,Memcached 客户端还是通过算法从服务器列表查询哪台服务器存有 Key 为 tokyo 的 Value(即选择刚刚 Set 到了哪台服务器),如果查到,则向查到的服务器请求返回 Key 为 tokyo 的数据。
1.1. Memcached 内存管理机制
Memcached 通过预分配指定的内存空间来存取数据,所有的数据都保存在 memcached 内置的内存中。利用 Slab Allocation 机制来分配和管理内存。按照预先规定的大小,将分配的内存分割成特定长度的内存块,再把尺寸相同的内存块分成组,这些内存块不会释放,可以重复利用。当存入的数据占满内存空间时,Memcached 使用 LRU 算法自动删除不使用的缓存数据。Memcached 是为缓存系统设计的,因此没有考虑数据的容灾问题,和机器的内存一样,重启机器将会丢失,如果希望服务重启数据依然能保留,那么就需要 sina 网开发的 Memcached 持久性内存缓冲系统,当然还有常见的 NOSQL 服务如 redis。默认监听端口:11211
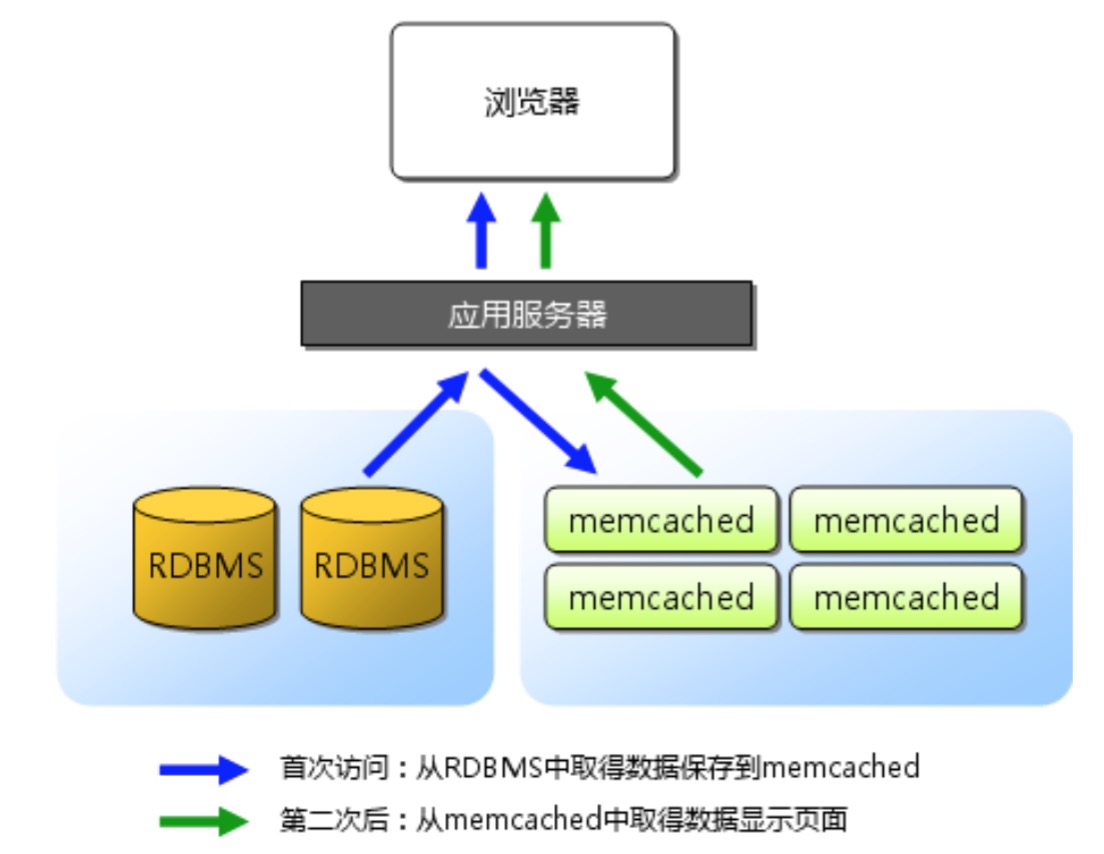
1.2. Memcached 算法
1.2.1. 余数计算分散法
余数计算分散法是 memcached 标准的分布式方法,算法如下:
CRC($key)%N
- 求得传入键的整数哈希值( int hashCode )。
- 使用计算出的 hashCode 除以服务器台数 (N) 取余数( C = hashCode % N )
- 在 N 台服务器中选择序号为 C 的服务器。
余数计算的方法简单,数据的分散性也相当优秀,但也有其缺点。 那就是当添加或移除服务器时,缓存重组的代价相当巨大。 添加服务器后,余数就会产生巨变,这样就无法获取与保存时相同的服务器, 从而影响缓存的命中率。
1.2.2. Consistent Hashing 算法
首先求出 memcached 服务器节点的哈希值,并将其分配到 0 ~ 2^32 的圆上,这个圆我们可以把它叫做值域,然后用同样的方法求出存储数据键的哈希值,并映射到圆上。然后从数据映射到的位置开始顺时针查找,将数据保存到找到的最近服务器上,如果超过 0~2^32 仍找不到,就会保存在第一台 memcached 服务器上:

memcached 基本原理:
再抛出上面的问题,如果新添加或移除一台机器,在 consistent Hashing 算法下会有什么影响。上图中假设有四个节点,我们再添加一个节点叫 node5:

添加了 node 节点之后:
node5 被放在了 node4 与 node2 之间,本来映射到 node2 和 node4 之间的区域都会找到 node4,当有 node5 的时候,node5 和 node4 之间的还是找到 node4,而 node5 和 node2 之间的此时会找到 node5,因此当添加一台服务器的时候受影响的仅仅是 node5 和 node2 区间。由于 KEY 总是顺时针查找距离其最近的节点,因此新加入的节点只影响整个环中的一部分
1.2.3. 优化的 Consistent Hashing 算法
上面可以看出使用 consistent Hashing 最大限度的抑制了键的重新分配,且有的 consistent Hashing 的实现方式还采用了虚拟节点的思想。问题起源于使用一般 hash 函数的话,服务器的映射地点的分布非常不均匀,从而导致数据库访问倾斜,大量的 key 被映射到同一台服务器上。为了避免这个问题,引入了虚拟节点的机制,为每台服务器计算出多个 hash 值,每个值对应环上的一个节点位置,这种节点叫虚拟节点。而 key 的映射方式不变,就是多了层从虚拟节点再映射到物理机的过程。这种优化下尽管物理机很少的情况下,只要虚拟节点足够多,也能够使用得 key 分布的相对均匀。